Why Polling Breaks
Every Applications eventually need to know when something is changed in the database, New user Signed up, Orders Placed, Payments failed and other operations…,it is need to be known for other parties for example we may need to send Orders data to inventory service to subtract from available products, may need to notify the user when payment is failed so we may send to notifications service, or need to sync the search indexes of the product… and other the naive approach for this problem is Polling, looking for changes for in intervals by polling from our database, at glance it works until it doesn’t, here are some of the issues that makes it polling difficult and not feasible for data changes:
- it compete with other database connections for the connection pool.
- it doesn’t track hard delete changes which lead to inconsistent data.
- it create unnecessary load on the database, imagine bashing the database for changes for every intervals.
maybe tracking hard delete can be minimized by using Transactional Outbox Pattern, but it comes with its own complexity ( implementing it can be application overhead ) and it can’t track all changes the database base as the database can be accepting a change from other parties other than the applications. so there must be other way right? yeah there is, this is where Eve comes in.
Eve Doesn’t Poll, She Listens
I know it is a little bit lame but if you don’t get the joke i was talking bout Eve The Eavesdropper who like to listen what Alice and Bob is talking bout, but here i learn something from her, and i want to listen instead of polling but not Alice And Bob conversation, rather any conversation with my PostgreSQL database. and this is called Change Data Capture and there are already battle tested tools like Debezium. and it uses the built-in Postgres replications Mechanism.
Replications
Postgres support 2 type of replications
- Physical Replications: it Sends raw disk page changes. The replica must be identical hardware/OS/Postgres version. Used for HA ( Highly Available ) standbys and read replicas. and you can’t selectively replicate one table or one change. and the WAL Level for this type of replications is replica.
- Logical Replications: this is what we need, on this type Postgres decodes the WAL into human-readable row operations. like INSERT, UPDATE , DELETE with actual column values. so we can filter by table, transform, fan out to multiple consumers.
What Is The WAL?
Incase you are not familar with the term, WAL( Write-Ahead Log ) is an append-only, sequential file that records every change before it touches the actual table data. And every record has an LSN (Log Sequence Number), which is just a monotonically increasing byte offset into the WAL stream. Think of WAL as a global, tamper-proof changelog. and it was designed for crash recovery, if Postgres dies mid-write, it replays the WAL on restart. and it has levels as i vagely mention it earlier, the levels are:
- wal_level = minimal : where Postgres used it only just for crash recovery.
- wal_level = replica : where Postgres is now on Physical replica mode.
- wal_level = logical : this is what we are gonna use, it is logical replications mode and it have full row-level changes and CDC just taps into that same stream.
My CDC Package
when i found about CDC and Debezium, my first question was how does it work? and the second one is how hard is it to implement something like this, as The Great Richard feynman said “What i can’t create i don’t understand”. so it makes me curious to know what it does under the hood and decide to make not a tool like Debezium but an embedable Golang package that do the minimum to be called CDC package.
How our CDC Package works?
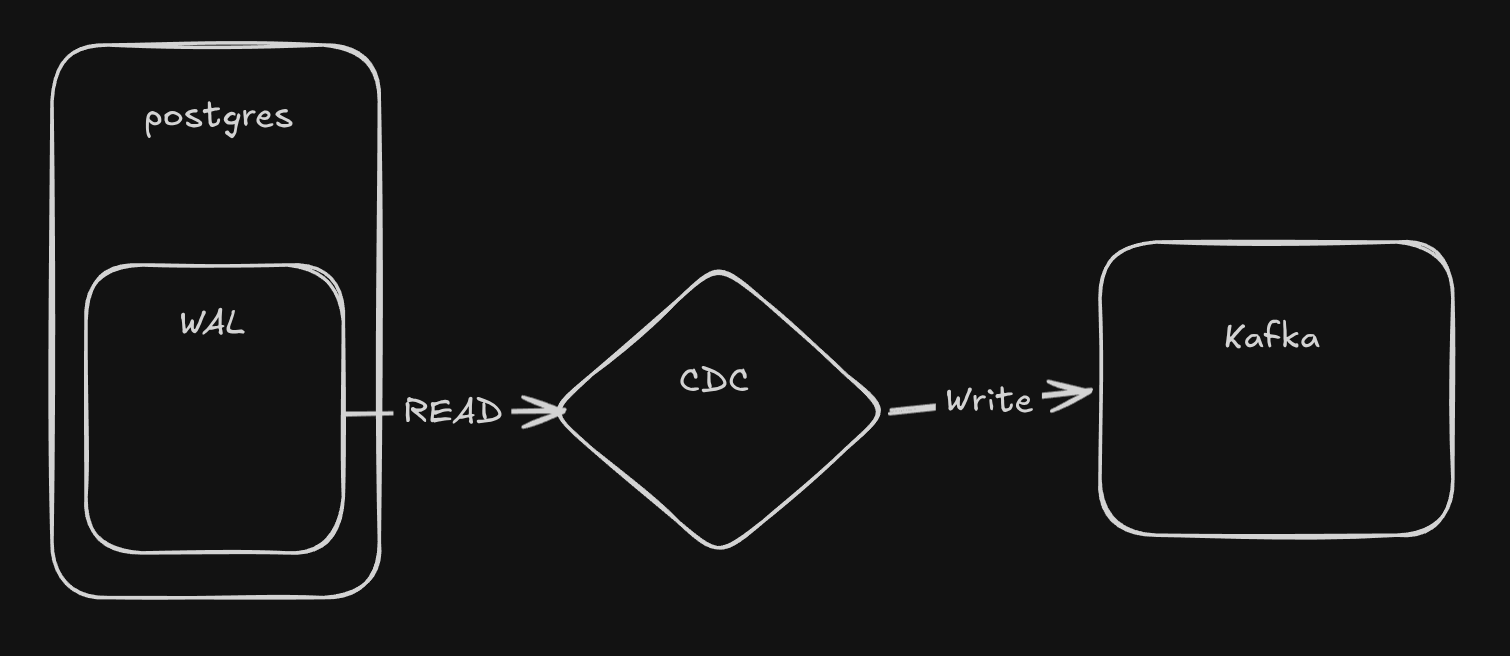
- PostgresSource: it connects to Postgres Instance, Create Replications Slot, Start Streaming using Pglogrepl, PglogRepl is Postgres Logical Replication library For Go, and It implement The Official Postgres Logical Replications Protocol and it uses pgoutput a built-in logical decoding plugin for Postgres.
- KafkaSink it receive the events and distribute to the consumers.
- Engine this Component is the one who coordinate the message flow, itread from Our source ( in our case Postgres WAL) and Push it to Our Sink (KafkaSink).
Interesting Details
LSN Acknowledgement
Arguably One of the most important thing to do while dealing with WAL is this one, We must make sure to Acknowledge the Postgres WAL if not it gonna lead to the WAL take all the Disk Space and Postgres will stop accepting operations. Why this happens? WAL Files are temporary by Design, they got written to disk as a series of Segment files, Usually each 16MB by default, and Postgres Does not keep them forever, it will recycle them ( meaning delete the file or rename for future WAL segments) once it Flushes to disk ( for crash recovery safety), all replica slots acknowledge them and it is no longer needed for the recovery purpose. so if we don’t acknowledge the LSN ( Log Sequence Number ) it will persist it till it gets Acknowledgement and lead to running out of Disk Space, and we must make sure to Acknowledge it after the Sink accepted the Event or it will lead to Data Inconsistency problem.
Resume From Failure
Our Engine may fail, we don’t know when it fails and where we are on the WAL LSN so how can we recover from it and keep the data consistency? Thanks to Postgres it help us on this cases, When we create a replications slot ( which is one of the first steps on replication protocol) Postgres track it like this:
pg_replication_slots:
| slot_name | restart_lsn | confirmed_flush_lsn |
|---|---|---|
| my_slot | 0/1A000000 | 0/19FFF000 |
so when we try to connect again we can fetch the LSN and continue from that. Notice restart_lsn is just little bit behind of confirmed_flush_lsn Postgres do it intentionally. and when we acknowledge the LSN we move confirmed_flush_lsn and Postgres set restart_lsn slightly before the confirmed one.
Bufferd Channel For Backpressure
The WAL stream can produce events faster than our Kafka sink can consume them. Without a buffer, the streaming goroutine would block every time the sink is slow, which creates unnecessary pressure back on the replication connection. By using a buffered channel of size 100, the streaming goroutine can keep pulling events from WAL without waiting for Kafka to catch up, the channel absorbs the burst. If the buffer fills up, the goroutine naturally slows down, which is exactly the backpressure behavior we want.
Reconnection Handling
As our source and sink are external dependencies, we must handle connection drops gracefully and retry with exponential backoff, adding a small random delay (jitter) between retries to avoid thundering herd issues when multiple clients reconnect at the same time.
Snippet
As spitting out the whole package is gonna make the blog bloated and unnecessary logic, i just put the maing loop where all the coordination is being done.
| |
Tradeoffs and What is missing
No Intial Snapshots: This is the “Day Zero” problem, our CDC stream only capture changes from the moment it start to listen,But there is already a lot of data on the table that is not being replicated cause our replications slot created after the data get populated, and we can’t not use queries cause it will lead to inconsistency cause it can miss changes if there are changes between the streaming starts and the SELECT statement finishs, so we either miss changes or apply them twice, Industry standard tools like Debezium solve this problem like this.
- Acquring a table lock ( or sometimes REPEATABLE READ snapshot isolations)
- Recording the LSN at the exact moment of the snapshot
- Doing the bulk SELECT at that LSN’s snapshot
- Starting the WAL stream from that exact same LSN.
- Release the lock
Schema Evoluions: currently we are not sending events for the schema changes and doesn’t have a schema registery to version and store the schemas so that the consumers can know what shape to expect.
Single SinK: currently we are using Kafka as our only sink but it can support other sinks like NATS JetStreams.
No Table Filtering: Currently the engine streams every change from every table, which isn’t ideal or practical. It should support an include/exclude list so consumers only get what they care about. A good example: if you’re using CDC to power an audit log and writing those audit events into an audit_logs table, without filtering you’d end up in an endless loop, the CDC engine picks up the audit insert, triggers another audit insert, and so on forever.
Conclusion
well we are at the end of the blog and i would like to thank you for reading it and forgive my bad jokes. i hope you get something out of it. Eve never missed a message and now neither does your backend by using CDC.
here is the repo for the project and i will try to add features that is missed cause most of them are very interesting. till next time see you friend.